這篇我想透過安裝和使用quantmod這個套件,用它來簡單分析股票作為R的入門介紹。
quantmod是什麼?
quantmod是一個R的套件,全名是 Quantitative Financial Modelling and Trading Framework for R ,它是一個用來做股價相關分析的套件。
接下來我試著用quantmod來獲取台灣加權指數的資訊。
(1).首先安裝和載入quantmod套件
於 R console輸入: install.packages("quantmod")
安裝好之後輸入:
library(quantmod)
getSymbols("^TWII", src="yahoo", from="2020-02-01", to="2020-11-17")
head(TWII)getSymbols 這個是quantmod提供的方法,^TWII 是 Yahoo 財經的股票代號,src 表示這個資料來源是yahoo資料庫。
head() 函數可以將資料印出前6筆方便檢視內容
執行後結果如下:
這個資料row(行)是表示日期,col(列)有6個欄位分別是Open(開盤價)
、High(盤中最高)、Low(盤中最低)、Close(收盤價)、Volume(交易量)、Adjusted(還原權值)有了這些資料我們就可以畫一個簡單的 Barchart,輸入 barChart(TWII)
簡單吧!
有了這些資料我們就可以進一步做分析,就拿最近最紅的護國神山台積電(2330)當例子好了。
要獲取台股資訊必須用"台股代號"+".TW"來給 quantmod,以台積電來說嘅票代號2330那我們就要給2330.TW、聯發科就是2454.TW,依此類推。
getSymbols("2330.TW", src="yahoo", from="2020-02-01", to="2020-11-17") #TSMC
TSMC.TW <- get("2330.TW")
chartSeries(TSMC.TW, theme = "white")
ma20 <- runMean(TSMC.TW[,4], n=20)
ma60 <- runMean(TSMC.TW[,4], n=60)
addTA(ma20, on=1, col="blue")
addTA(ma60, on=1, col="red")
TSMC.TW <- get("2330.TW") 因為台股代號是以數字開頭,無法直接給barchart或是chartseries 繪圖, 所以將取得的代號資訊給定一個名稱。
ma20 <- runMean(TSMC.TW[,4], n=20) 20日平均值,已便畫出20日均線
addTA(ma20, on=1, col="blue") 將20日平均值資料疊上圖表
執行結果:
還可以疊上
addWPR():威廉指標,
addDPO():DPO 是一個排除價格趨勢的震蕩指標。DPO>0,表明目前處於多頭市場;DPO<0,表明目前處於空頭市場。
再舉一個聯發科(2454.TW) 當例子:
library(quantmod)
getSymbols("2454.TW", src="yahoo", from="2020-02-01", to="2020-11-17")
MTEK.TW <- get("2454.TW")
chartSeries(MTEK.TW, theme = "white")
ma05 <- runMean(TSMC.TW[,4], n=5) #計算5日平均綫值
ma20 <- runMean(TSMC.TW[,4], n=20)
ma60 <- runMean(TSMC.TW[,4], n=60)
addTA(ma05, on=1, col="cyan") #畫出5日平均綫,青色
addTA(ma20, on=1, col="blue")
addTA(ma60, on=1, col="red")
addSAR() #畫出SAR拋物線指標
SAR指標的一般研判標準:
1.當股票股價從SAR曲線下方開始向上突破SAR曲線時,為買入信號,預示著股價一輪上升行情可能展開,投資者應迅速及時地買進股票。
2.當股票股價從SAR曲線上方開始向下突破SAR曲線時,為賣出信號,預示著股價一輪下跌行情可能展開,投資者應迅速及時地賣出股票。
執行結果:
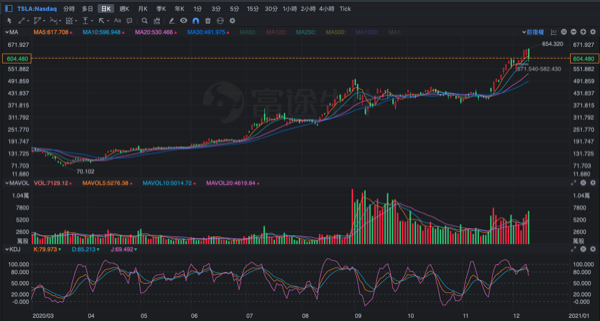
最後舉一個美股當例子,特斯拉 (TESLA美股代碼:TSLA):
library(quantmod)
getSymbols("TSLA", src="yahoo", from="2020-02-15", to="2020-11-18")
TSLA_price <- TSLA[, 4] #第4欄收盤價放到變數 TSLA_price
barChart(TSLA_price) #畫出2020-02-15~2020-11-18收盤線圖
addCCI() #加上順勢指標CCI
超賣超買指標:專門測量股價是否已經超出常態分布範圍。
一般來說,CCI上升超過100時,買入;當CCI下降低於-100,賣出。
執行結果:
有了quantmod 套件包在分析金融數據會變得很簡單,對於不懂網頁技術的人來說是一大利器,對初學R的人來說也是很好入門。
quantmod其他一些技術指標:
addCMF():Chaikin資金流量指標CMF
addCMO():Chande動量擺動指標CMO
addEMA():指數平均數指標EMA
addEnvelope():包絡線指標Envelope
addEVWMA():彈性成交量加權移動平均線指標EVWMA
addMACD():移動平均收斂發散指標MACD
addMomentum():動量指標Momentum
addExpiry():合約終止線Expiry
addSMI():隨機動量指標SMI
addDEMA():雙指數移動平均指標DEMA
addROC():變動率指標ROC
addRSI():相對強弱指標RSI
addWMA():加權移動平均線指標WMA
addZLEMA():零滯後指數移動平均ZLEMA