這一篇介紹 MoneyDJ 新聞頭條的爬蟲,所需要的套件有2個:
library(rvest) #爬蟲相關套件
library(stringr) #處理字串的套件
以 MoneyDJ 即時新聞網站為例,我們要先讀取它的首頁,運用套件的函數將該網頁的資料下載下來。
(1)讀取目標網頁:
url <- "http://blog.moneydj.com/news/"
doc <- read_html(url, encoding = "UTF-8")
(2)爬取目標網頁內容:
這部分需要爬取新聞標題,新聞標題子連結網址,發佈時間 三個部分
首先,爬取新聞標題
header <- doc %>%
html_nodes("#MainContent_Contents_sl_gvList a") %>%
html_text()
head(header, n = 5) #檢查前5個標題內容
其中 "#MainContent_Contents_sl_gvList a" 可以利用 Selector Gadget 來取得 CSS 的標題,
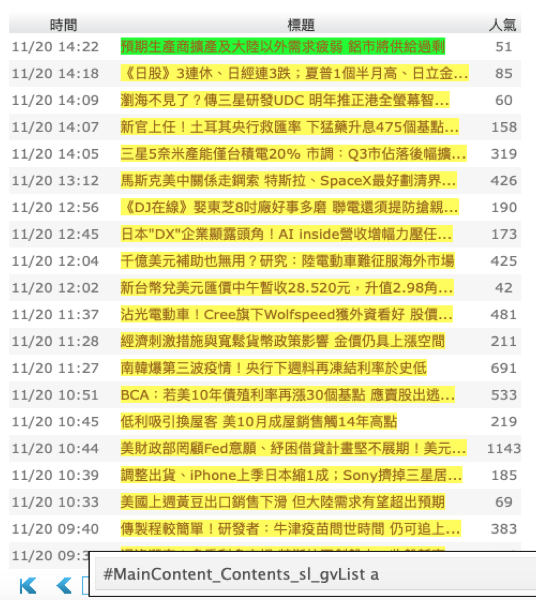
執行結果:

再來是爬取文章子連結:
link <- doc %>%
html_nodes("#MainContent_Contents_sl_gvList a") %>%
html_attr("href")
head(link, n = 5)
執行結果:

再來是發佈時間:
post_d <- doc %>%
html_nodes("#MainContent_Contents_sl_gvList td:nth-child(1)") %>%
html_text()
post_d <- gsub("\r\n|\\s", "", post_d)
head(post_d, n = 5)
用 Selector Gadget 圈選時要記得排除不需要的CSS,

執行結果:

post_d <- gsub("^(\\d{2})/(\\d{2})(\\d{2})", "\\1/\\2-\\3", post_d)

可以看到這20筆資料已經是正確的日期格式。
※註:會在月份與時間中間加上"-"是因為如果放一個空白,最後存成 csv 檔案時還是會被刪去,所以用"-"來分隔月份與時間。
最後就是利用剛剛爬取的文章子連結再去把文章內容爬下來:
article.all <- c()
for(i in 1:length(link)) {
url <- paste0("https://www.moneydj.com", link[i])
doc.a <- read_html(url)
article <- doc.a %>%
html_nodes("#MainContent_Contents_mainArticle") %>%
html_text() %>%
str_c(collapse = "")
article.all <- append(article.all, article)
}; article.all[20] #檢視第20筆文章內容

最後把這3筆資料(發布時間,文章標題,文章內容)整合成 data frame格式然後儲存成 csv 檔:
df <- data.frame(date = post_d, title = header, content = article.all)
df[1:5, 1:2]
write.csv(df, file="news.csv")
開啟 news.csv:

完整程式碼如下:
library(rvest)
library(stringr)
url <- "https://www.moneydj.com/KMDJ/News/NewsRealList.aspx?a=MB010000"
url <- "http://blog.moneydj.com/news/"
doc <- read_html(url, encoding = "UTF-8")
# 取得新聞標題
header <- doc %>%
html_nodes("#MainContent_Contents_sl_gvList a") %>%
#html_nodes("a") %>%
html_text()
head(header, n = 5) #檢查前5個標題內容
# 取得新聞的文章子連結
link <- doc %>%
html_nodes("#MainContent_Contents_sl_gvList a") %>%
#html_nodes("a") %>%
html_attr("href")
head(link, n = 5)
# 取得發布時間
post_d <- doc %>%
html_nodes("#MainContent_Contents_sl_gvList td:nth-child(1)") %>%
html_text()
post_d <- gsub("\r\n|\\s", "", post_d)
head(post_d, n = 5)
post_d <- gsub("^(\\d{2})/(\\d{2})(\\d{2})", "\\1/\\2-\\3", post_d); post_d
# 先創造一個空的物件,將所有文章內容合併在同一個物件中
article.all <- c()
for(i in 1:length(link)) {
url <- paste0("https://www.moneydj.com", link[i])
doc.a <- read_html(url)
article <- doc.a %>%
html_nodes("#MainContent_Contents_mainArticle") %>%
html_text() %>%
str_c(collapse = "")
article.all <- append(article.all, article)
}; article.all[20] #檢視第20筆文章內容
df <- data.frame(date = post_d, title = header, content = article.all)
df[1:5, 1:2] #檢視前5筆,1~2欄的資料
write.csv(df, file="news.csv") #寫入 news.csv 檔案




沒有留言:
張貼留言