搭最近很熱門的00940之亂,來講解一下如何爬取台股ETF的資料
我用MoneyDJ這個網站做範例,以元大0050來說淨值的網頁是:
https://www.moneydj.com/ETF/X/Basic/Basic0003.xdjhtm?etfid=0050.TW基本資料的網頁是:
https://www.moneydj.com/ETF/X/Basic/Basic0004.xdjhtm?etfid=0050.TW報酬分析的網頁是:
https://www.moneydj.com/ETF/X/Basic/Basic0008.xdjhtm?etfid=0050.TW網址的部分差異就是Basic003, Basic004, Basic008,等一下就用替換字串的方式處理
淨值網頁畫面如下:
html標籤分別是table3(最後一日淨值資料),table5,table6(過去30天的淨值資料),ttitle(ETF名稱),那我用BeautifulSoup去實作就如下:
# ETF淨值表格
url = 'https://www.moneydj.com/ETF/X/Basic/Basic0003.xdjhtm?etfid=0050.TW'
response = requests.get(url)
response.encoding = 'utf-8'
web_content = response.text
soup = BeautifulSoup(web_content, 'lxml')
# 取得 title
title = soup.title.string.strip().split('-')
print(f'ETF名稱: {title[0]} ({title[1]})')
# 日期較近的15天
data1 = soup.select('table')[5]
lst1 = pd.read_html(data1.prettify())
df1 = lst1[0]
# 日期較遠的15天
data2 = soup.select('table')[6]
lst2 = pd.read_html(data2.prettify())
df2 = lst2[0]
# 合併為30天, 並依日期排序
df = pd.concat([df1, df2]).sort_values(by=['日期']).reset_index(drop=True)
# 日期取 mm/dd
pattern = r'\d{4}/(\d{2}/\d{2})'
df['日期'] = df['日期'].replace(pattern, r'\1', regex=True)
min = df['淨值'].min() # 提取淨值30日最低
max = df['淨值'].max() # 提取淨值30日最高
min_date = df[df['淨值'] == min]['日期'].values[0] # 提取淨值最低日期
max_date = df[df['淨值'] == max]['日期'].values[0] # 提取淨值最高日期
df.tail(10)
其中日期 yyyy/mm/dd 的格式我用正規式替換成 mm/dd 格式
輸出結果(最後10筆(日)資料):
接著是基本資料的網頁畫面,我要抓取的是ETF經理人資料:
這個html標籤是table3裡面的資訊,寫法就是:
# ETF經理人
url = 'https://www.moneydj.com/ETF/X/Basic/Basic0003.xdjhtm?etfid=0050.TW'
url = re.sub('[B|b]asic0003', 'Basic0004', url)
response = requests.get(url)
response.encoding = 'utf-8'
web_content = response.text
soup = BeautifulSoup(web_content, 'lxml')
data = soup.select('table')[3]
lst = pd.read_html(data.prettify())
dfs = lst[0]
print('ETF名稱:', dfs.iloc[0, 1])
print('經理人:', dfs.iloc[15, 1])
剛剛已說了網址的部分就是把Basic0003換成Basic0004,我看了這個網站的網址也些是大寫有些小寫所以避免沒換替換成功就用正規式表示待替換的[B|b] (大寫B或小寫b)換成'Basic0004',取出的html表格放在lst變數長得像這樣:
我只要取出 list0 的第15筆資料經理人名稱就好,寫法如下:
# 取出ETF經理人
url = 'https://www.moneydj.com/ETF/X/Basic/Basic0003.xdjhtm?etfid=0050.TW'
url = re.sub('[B|b]asic0003', 'Basic0004', url)
response = requests.get(url)
response.encoding = 'utf-8'
web_content = response.text
soup = BeautifulSoup(web_content, 'lxml')
data = soup.select('table')[3]
lst = pd.read_html(data.prettify())
dfs = lst[0]
print('ETF名稱:', dfs.iloc[0, 1])
print('經理人:', dfs.iloc[15, 1])
輸出結果:
最後一個是"報酬分析"頁面的畫面如下:
這個html標籤是table3裡面的資訊,當中有市價與淨值兩行,我取淨值的資料,至於差異各位自行去查,寫法如下:
# ETF報酬分析 Total returns
url = 'https://www.moneydj.com/ETF/X/Basic/Basic0003.xdjhtm?etfid=0050.TW'
url = re.sub('[B|b]asic0003', 'Basic0008', url)
response = requests.get(url)
response.encoding = 'utf-8'
web_content = response.text
soup = BeautifulSoup(web_content, 'lxml')
data = soup.select('table')[3]
lst = pd.read_html(data.prettify())
df = lst[0]
df
輸出結果:
將淨值的資料存入變數:
# 取淨值資料(Net Asset Value,NAV)
tr_d = df['一日'][1]
tr_w = df['一週'][1]
tr_m = df['一個月'][1]
tr_3m = df['三個月'][1]
tr_6m = df['六個月'][1]
tr_1y = df['一年'][1]
tr_3y = df['三年'][1]
tr_5y = df['五年'][1]
tr_10y = df['十年'][1]
tr_si = df['成立日'][1]
將上面三個部分寫成函數就可以了,我以台灣前7大熱門ETF來當範例,完整程式如下:
from bs4 import BeautifulSoup
import urllib.request
import pandas as pd
import json, requests, os, re
fund_dict = {'元大高股息':'https://www.moneydj.com/etf/x/basic/basic0003.xdjhtm?etfid=0056.tw',
'國泰永續高股息':'https://www.moneydj.com/etf/x/basic/basic0003.xdjhtm?etfid=00878.tw',
'元大台灣50':'https://www.moneydj.com/ETF/X/Basic/Basic0003.xdjhtm?etfid=0050.TW',
'富邦台50':'https://www.moneydj.com/etf/x/basic/basic0003.xdjhtm?etfid=006208.tw',
'元大台灣高息低波':'https://www.moneydj.com/ETF/X/Basic/Basic0003.xdjhtm?etfid=00713.TW',
'群益台灣精選高息':'https://www.moneydj.com/ETF/X/Basic/Basic0003.xdjhtm?etfid=00919.TW',
'元大台灣價值高息':'https://www.moneydj.com/ETF/X/Basic/Basic0003.xdjhtm?etfid=00940.TW'}
#(1)取得ETF經理人
def get_fund_manager(url):
url = re.sub('[B|b]asic0003', 'Basic0004', url)
response = requests.get(url)
response.encoding = 'utf-8'
web_content = response.text
soup = BeautifulSoup(web_content, 'lxml')
data = soup.select('table')[3]
lst = pd.read_html(data.prettify())
dfs = lst[0]
return dfs.iloc[15, 1] #ETF manager
#(2)取得ETF淨值資料
def get_fund_price(url, name):
response = requests.get(url)
response.encoding = 'utf-8'
web_content = response.text
soup = BeautifulSoup(web_content, 'lxml')
# 取得 title
title = soup.title.string.strip().split('-')
fund_name = f'{title[0]} ({title[1]})'
# 日期較近的15天
data1 = soup.select('table')[5]
lst1 = pd.read_html(data1.prettify())
df1 = lst1[0]
# 日期較遠的15天
data2 = soup.select('table')[6]
lst2 = pd.read_html(data2.prettify())
df2 = lst2[0]
# 合併為30天, 並依日期排序
df = pd.concat([df1, df2]).sort_values(by=['日期']).reset_index(drop=True)
# 日期取 mm/dd
pattern = r'\d{4}/(\d{2}/\d{2})'
df['日期'] = df['日期'].replace(pattern, r'\1', regex=True)
min = df['淨值'].min() # 提取30日淨值最低
max = df['淨值'].max() # 提取30日淨值最高
min_date = df[df['淨值'] == min]['日期'].values[0] # 提取淨值最低日期
max_date = df[df['淨值'] == max]['日期'].values[0] # 提取淨值最高日期
date = df.tail(1).values.tolist()[0][0] # 最後資料日期
nav = df.tail(1).values.tolist()[0][1] # 最後淨值(Net Asser Value)
price = df.tail(1).values.tolist()[0][2] # 最後市價(Market price)
# 取得漲跌百分比表格
data = soup.select('table')[3]
lst = pd.read_html(data.prettify())
df3 = lst[0]
updown = df3['漲跌'].loc[1] #漲/跌 NAV Change
pct = df3['漲跌幅(%)'].loc[1] #漲跌百分比 NAV Change Percent
return fund_name, [date, nav, updown, pct, max, min]
#(3)取得ETF報酬分析資料
def get_fund_total_return(url):
url = re.sub('[B|b]asic0003', 'Basic0008', url)
response = requests.get(url)
response.encoding = 'utf-8'
web_content = response.text
soup = BeautifulSoup(web_content, 'lxml')
data = soup.select('table')[3]
lst = pd.read_html(data.prettify())
df = lst[0]
tr_1d = df['一日'][1]
tr_1w = df['一週'][1]
tr_1m = df['一個月'][1]
tr_3m = df['三個月'][1]
tr_6m = df['六個月'][1]
tr_1y = df['一年'][1]
tr_3y = df['三年'][1]
tr_5y = df['五年'][1]
tr_10y = df['十年'][1]
tr_si = df['成立日'][1]
return [tr_1m, tr_3m, tr_6m, tr_1y, tr_3y, tr_si]
df = pd.DataFrame()
for name in fund_dict.keys():
url = fund_dict[name]
manager_df = pd.DataFrame()
#(1)取得ETF淨值資料
fund_name, price_list = get_fund_price(url, name)
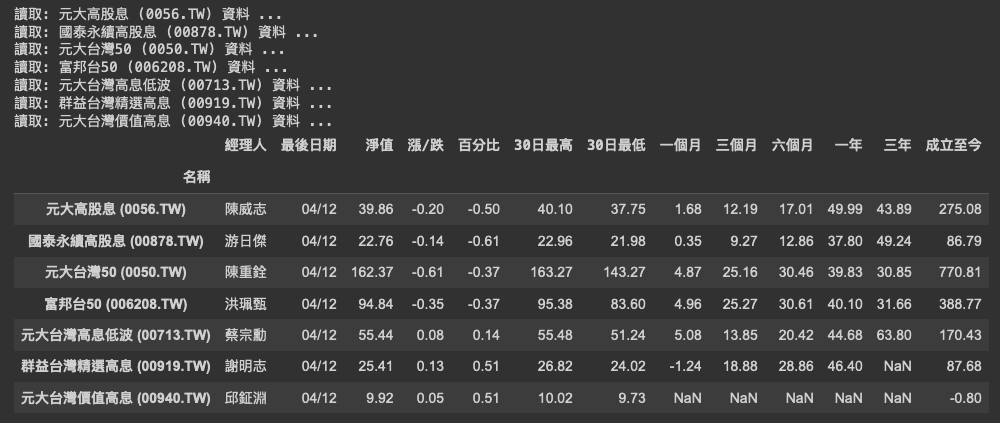
print(f'讀取: {fund_name} 資料 ...')
price_list.insert(0, fund_name)
cols = ['名稱', '最後日期', '淨值', '漲/跌', '百分比', '30日最高', '30日最低']
price_df = pd.DataFrame([price_list], columns=cols)
#(2)取得ETF經理人
fund_manager = get_fund_manager(url)
manager_df = pd.DataFrame([fund_name], columns=['名稱']).set_index('名稱')
manager_df['經理人'] = fund_manager
# 合併 manager_df price_df
manager_df = manager_df.merge(price_df, on='名稱')
#(3)取得報酬分析資料
returns_list = get_fund_total_return(url)
returns_list.insert(0, fund_name)
cols = ['名稱', '一個月', '三個月', '六個月', '一年', '三年', '成立至今']
returns_df = pd.DataFrame([returns_list], columns=cols)
# 合併 manager_df, returns_df
manager_df = manager_df.merge(returns_df, on='名稱' ).copy()
manager_df.set_index('名稱', inplace=True)
df = pd.concat([df, manager_df])
df
輸出結果如下:
這樣就可以看到這些發行的ETF的淨值,報酬資料,將程式放入定時執行後產生報表用email寄出,就可以每天知道他們的變化。




























 d
d









